 |
| Dilbert - by Scott Adams |
Things are a little confusing out there I think in part because not enough care is taken in defining terms before assessing pros and cons. And when terms are defined, they sometimes include desired outcomes as a part of their definition. For example, blockchain is often described as consisting of (among other things) an immutable ledger. This is like defining a titanic to be an unsinkable ship.
So what do people mean when they bandy about the term blockchain? I recently had a chance to learn about the project from a corporate perspective as represented by Ed Corno of IBM (see IBM Blockchain), the other member of the panel I mentioned above. From Ed's slide deck we have the following definition:
Blockchain: a shared, replicated, permissioned ledger with consensus, provenance, immutability and finality.Well, if this is what blockchain is, then maybe I want one too! The issue I have with this definition (apart from the fact that it confounds descriptive elements with desired outcomes) is that it glosses over what I consider to be an important defining characteristic of blockchain: the consensus mechanism. Loosely speaking, there are two ways to achieve consensus. One is reputation-based (trust) and the other is game-based (trustless).
I'm not 100% sure, but I believe the corporate versions of blockchain are likely to stick to the standard model of reputation-based accounting. In this case, the efficiency gains of "blockchain" boil down to the gains associated with making databases more synchronized across trading partners, more cryptographically secure, more visible, more complete, etc. In short, there is nothing revolutionary or radical going on here -- it's just the usual advancement of the technology and methods associated with the on-going problem of database management. Labeling the endeavor blockchain is alright, I guess. It certainly makes for good marketing!
On the other hand, game-based blockchains--like the one that power Bitcoin--are, in my view, potentially more revolutionary. But before I explain why I think this, I want to step back a bit and describe my bird's eye view of what's happening in this space.
A Database of Individual Action Histories
The type of information that concerns us here is not what one might label "knowledge," say, as in the recipe for a nuclear bomb. The information in question relates more to a set of events that have happened in the past, in particular, events relating to individual actions. Consider, for example, "David washed your car two days ago." This type of information is intrinsically useless in the sense that it is not usable in any productive manner. In addition to work histories like this, the same is true of customer service histories, delivery/receipt histories, credit histories, or any performance-related history. And yet, people value such information. It forms the bedrock of reputation and perhaps even of identity. As such, it is frequently used as a form of currency.
Why is intrinsically useless history of this form valued? A monetary theorist may tell you it's because of a lack of commitment or a lack of trust (see Evil is the Root of All Money). If people could be relied upon to make good on their promises a priori, their track records would largely be irrelevant from an economic perspective. A good reputation is a form of capital. It is valued because it persuades creditors (believers) that more reputable agencies are more likely to make good on their promises. We keep our money in a bank not because we think bankers are angels, but because we believe the long-term franchise value of banking exceeds the short-run benefit a bank would derive from appropriating our funds. (Well, that's the theory, at least. Admittedly, it doesn't work perfectly.)
Note something important here. Because histories are just information, they can be created "out of thin air." And, indeed, this is the fundamental source of the problem: people have an incentive to fabricate or counterfeit individual histories (their own and perhaps those of others) for a personal gain that comes at the expense of the community. No society can thrive, let alone survive, if its members have to worry excessively about others taking credit for their own personal contributions to the broader community. I'm writing this blog post in part (well, perhaps mainly) because I'm hoping to get credit for it.
Since humans (like bankers) are not angels, what is wanted is an honest and immutable database of histories (defined over a set of actions that are relevant for the community in question). Its purpose is to eliminate false claims of sociable behavior (acts which are tantamount to counterfeiting currency). Imagine too eliminating the frustration of discordant records. How much time is wasted in trying to settle "he said/she said" claims inside and outside of law courts? The ultimate goal, of course, is to promote fair and efficient outcomes. We may not want something like this creepy Santa Claus technology, but something similar defined over a restricted domain for a given application would be nice.
Organizing History
Let e(t) denote a set of events, or actions (relevant to the community in question), performed by an individual at date t = 1,2,3,... An individual history at date t is denoted
h(t-1) = { e(t-1), e(t-2), ..., e(0) }, t = 1,2,3,...
Aggregating over individual events, we can let E(t) denote the set of individual actions at date t, and let H(t-1) denote the communal history, that is, the set of individual histories of people belonging to the community in question:
H(t-1) = { E(t-1), E(t-2), ... , E(0) }, t = 1,2,3,...
Observe that E(t) can be thought of as a "block" of information (relating to a set of actions taken by members of the community at date t). If this is so, then H(t-1) consists of time-stamped blocks of information connected in sequence to form a chain of blocks. In this sense, any database consisting of a complete history of (community-relevant) events can be thought of as a "blockchain."
Note that there are other ways of organizing history. For example, consider a cash-based economy where people are anonymous and let e(t) denote acquisitions of cash (if positive) or expenditures of cash (if negative). Then an individual's cash balances at the beginning of date t is given by h(t-1) = e(t-1) + e(t-2) + ... + e(0). This is the sense in which "money is memory." Measuring a person's worth by how much money they have serves as a crude summary statistic of the net contributions they've made to society in the past (assuming they did not steal or counterfeit the money, of course). Another way to organize history is to specify h(t-1) = { e(t-1) }. This is the "what have you done for me lately?" model of remembering favors. The possibilities are endless. But an essential component of blockchain is that it contains a complete history of all community-relevant events. (We could perhaps generalize to truncated histories if data storage is a problem.)
Database Management Systems (DBMS) and the Read/Write Privilege
Alright then, suppose that a given community (consisting of people, different divisions within a firm, different firms in a supply chain, etc.) wants to manage a chained-block of histories H(t-1) over time. How is this to be done?
Along with a specification of what is to constitute the relevant information to be contained in the database, any DBMS will have to specify parameters restricting:
1. The Read Privilege (who, what, and how);
2. The Write Privilege (who, what, and how).
That is, who gets to gets to read and write history? Is the database to be completely open, like a public library? Or will some information be held in locked vaults, accessible only with permission? And if by permission, how is this to be granted? By a trusted person, by algorithm, or some other manner? Even more important is the question of who gets to write history. As I explained earlier, the possibility for manipulation along this dimension is immense. How to guard against to attempts to fabricate history?
Historically, in "small" communities (think traditional hunter-gatherer societies) this was accomplished more or less automatically. There are no strangers in a small, isolated village and communal monitoring is relatively easy. Brave deeds and foul acts alike, unobserved by some or even most, rapidly become common knowledge. This is true even of the small communities we belong to today (at work, in clubs, families, friends, etc.). Kocherlakota (1996) labels H(t-1) in this scenario "societal memory." I like to think of it as a virtual database of individual histories living in a distributed ledger of brains talking to each other in a P2P fashion, with additions to, and maintenance of, the shared history determined through a consensus mechanism. In this primitive DBMS, read and write privileges are largely open, the latter being subject to consensus. It all sounds so...blockchainy.
While the primitive "blockchain" described above works well enough for small societies, it doesn't scale very well. Today, the traditional local networks of human brains have been augmented (and to some extent replaced) by a local and global networks of computers capable of communicating over the Internet. Achieving rapid consensus in a large heterogeneous community characterized by a vast flows of information is a rather daunting task.
The "solution" to this problem has largely taken the form of proprietary databases with highly restricted read privileges managed by trusted entities who are delegated the write privilege. The double-spend problem for digital money, for example, is solved by delegating the record-keeping task to a bank, located within a banking system, performing debit/credit operations on a set of proprietary ledgers connected to a central hub (a clearing agency) typically managed by a central bank.
The Problem and the Blockchain Solution
Depending on your perspective, the system that has evolved to date is either (if you are born before 1980) a great improvement over how things operated when we were young, or (if you are born post 1980) a hopelessly tangled hodgepodge of networks that have trouble communicating with each other and are intolerably vulnerable to data breaches (see figure below, courtesy Ed Corno of IBM).
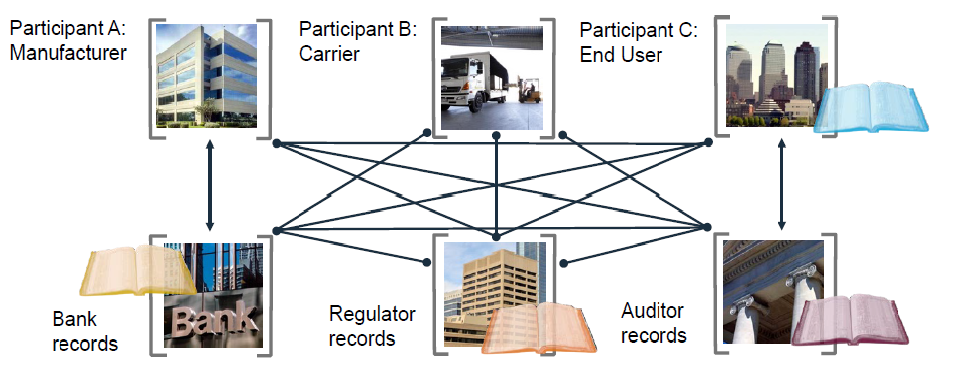
The solution to this present state of affairs is presented as blockchain (defined earlier) which Ed depicts in the following way,


The point I'm making is, if we're ultimately going to depend on reputation-based consensus mechanisms, then we need no new innovation (like blockchain) to organize a database. While I'm no expert in the field of database management, it seems to me that standard protocols, for example, in the form of SQL Server 2017, can accommodate what is needed technologically and operationally (if anyone disagrees with me on this matter, please comment below).
Extending the Write Privilege: Game-Based Consensus
As explained above, extending the read-privilege is not a problem technologically. We are all free to publish our diaries online, creating a shared-distributed ledger of our innermost thoughts. Extending the write-privilege to unknown or untrusted parties, however, is an entirely different matter. Of course, this depends in part on the nature of the information to be stored. Wikipedia seems to work tolerably well. But its hard to use Wikipedia as currency. This is not the case with personal action histories. You don't want other people writing your diary!
Well, fine, so you don't trust "the Man." What then? One alternative is to game the write privilege. The idea is to replace the trusted historian with a set of delegates drawn from the community (a set potentially consisting of the entire community). Next, have these delegates play a validation/consensus game designed in such a way that the equilibrium (say, Nash or some other solution concept) strategy profile chosen by each delegate at every date t = 1,2,3,... entails: (1) No tampering with recorded history H(t-1); and (2) Only true blocks E(t) are validated and appended to the ledger H(t-1).
What we have done here is replace one type of faith for another. Instead of having faith in mechanisms that rely on personal reputations, we must now trust that the mechanism governing non-cooperative play in the validation/consensus game will deliver a unique equilibrium outcome with the desired properties. I think this is in part what people mean when I hear them say "trust the math."
Well, trusting the math is one thing. Trusting in the outcome of a non-cooperative game is quite another matter. The relevant field in economics is called mechanism design. I'm not going to get into details here, but suffice it to say, it's not so straightforward designing mechanisms with sure-fire good properties. Ironically, mechanisms like Bitcoin will have to build up trust the old-fashioned way--through positive user experience (much the same way most of us trust our vehicles to function, even if we have little idea how an internal combustion engine works).
Of course, the same holds true for games based on reputational mechanisms. The difference is, I think, that non-cooperative consensus games are intrinsically more costly to operate than their reputational counterparts. The proof-of-work game played by Bitcoin miners, for example, is made intentionally costly (to prevent DDoS attacks) even though validating the relevant transaction information is virtually costless if left in the hands of a trusted validator. And if a lack of transparency is the problem for trusted systems, this conceptually separate issue can be dealt with by extending the read-privilege communally.
Having said this, I think that depending on the circumstances and the application, the cost associated with a game-based consensus mechanism may be worth incurring. I think we have to remain agnostic on this matter for now and see how future developments unfold.
Blockchain: Powering DAOs
If Blockchain (with non-cooperative consensus) has a comparative advantage, where might it be? To me, the clear application is in supporting Decentralized Autonomous Organizations (DAOs). A DAO is basically a set of rules written as a computer program. Because it possesses no central authority or node, it can offer tailor-made "legal" systems unencumbered by prevailing laws and regulations, at least, insofar as transactions are limited to virtual fulfillments (e.g., debit/credit operations on a ledger).
Bitcoin is an example of a DAO, though the intermediaries that are associated with Bitcoin obviously are not. Ethereum is a platform that permits the construction of more sophisticated DAOs via the use of smart contracts. The comparative advantages of DAOs are that they permit: (1) a higher degree of anonymity; (2) permissionless access and use; and (3) commitment to contractual terms (smart contracts).
It's not immediately clear to me what value these comparative advantages have for registered businesses. There may be a role for legally compliant smart contracts (a tricky business for international transactions). But perhaps the potential is much more than I can presently imagine. Time will tell.
Link to my past posts on the subject of Bitcoin and Blockchain.
Hi David, amazing and very detailed write-up. Am I right, Bitcoin was introduced by software developers to the world in 2009 and perhaps this is the only write-up where author has mentioned why we do not need it. I really enjoyed reading this.
ReplyDeleteHi David - this is why I argue there are two revolutions underway, both addressing the same (technical) requirement but each having very different trust/game-theoretic assumptions and hence address very different 'business' requirements. 1) the game-based consensus revolution (as you describe it) which, at its core, attempts to provide censorship-resistance with respect to transaction confirmation and so enables things like cryptocurrencies. 2) a more permissioned (perhaps more centralised) revolution which attempts to enable applications to be built at the level of industries/markets rather than firms (as is presently the case, hence needing to endless, mindless reconciliation between firms) without requiring the introduction of new business-level intermediaries such as CCPs, etc. At the technical level they both rest on the idea of 'trust but verify' (in that nobody blindly believes what a database operated by somebody else tells them; they run their own copy of the software, which verifies for themselves) but they differ in who/what they trust to determine if a transaction has been confirmed or not. This latter point is important... the ONLY service that, say, bitcoin miners are providing at their core is transaction ordering... ie they are the arbiters of which transaction came 'first' in the event that two happen to collide (eg a double-spend). This is the thing you can't decide for yourself by independently valuing a chain of transactions. Revolution 1) typically imposes no limits/rules on who can participate in the confirmation process (and hence limits censorship) but at the cost (at least with today's algorithms) of only probabilistic finality. 2) typically is more strict on how consensus is formed in order to deliver finality but at the cost of (potentially) enabling those parties to suppress transactions.
ReplyDeleteI know my formulation is not universally accepted but I think it's important to write it this way because it explains why "just use a centralised database" misses the point. A centralised database is designed on the assumption that the operator is trusted and the users are the adversaries (hence strict read/write permissions, etc). But the problem we're trying to solve when deploying an application to an entire market is to allow each firm to run its *own* copy of the application so that users in that firm can trust its output but without requiring that copy of the app to blindly trust what it is told by other people's copies. This "each party runs the (same) logic" is one of the key steps forward I think we're seeing. Sorry if this isn't fully clear... I've written it quickly and I probably need to tighten up part of the argument. (I'm also working on a blog post about "decentralised software for decentralised markets" which pursues some of the same themes... it should be out early next week)
Richard, thank you for this thoughtful response.
DeleteIf I've missed the point with my "just use a centralized database," then I'm sure I'm not alone! To me, having the data live on a central ledger (with multiple copies distributed however one likes) open for all to see does not necessarily mean (to me) that "a centralized database is designed on the assumption that the operator is trusted." I admit, however, that you are likely to know better than I what is involved here given that you're working in the space. I look forward to seeing a practical application of enterprise-level blockchain. Cheers.
Hi David. I freely admit I could be totally wrong! I tried to capture what I _think_ is a useful insight here: https://gendal.me/2016/11/08/on-distributed-databases-and-distributed-ledgers/ . The devil in the detail with your comment above is this: "having the data live on a central ledger (with multiple copies distributed however one likes)". The problem is: when that information is "distributed" to me, who am I trusting for its accuracy?
ReplyDeleteImagine the information was something like: "Barclays Bank now owes Richard GBP1M". And imagine further that the operator of this central database is not in fact Barclays (since it is also used to track balances at other banks or manage other types of legal agreements). Who would be willing to run such a system in a way that would convince other people to use it (think of the liability if there was a mistake!) Put the other way, who would be willing to use such a system _unless_ the operator carried liability?
Simply saying "the data is distributed" (somehow) doesn't answer any questions: if I receive data through my front door then I either have to trust the person who sent it to me as to its accuracy/provenance or I need to independently check it for myself.
In scenarios where you can do the former (eg because the operator of the centralised databases is ALSO the firm whose liabilities it represents - as in today's banking system and associated computer systems) then just use a centralised database. But if you need to check the data yourself (by examining historical records, checking any asset movements were correctly signed and linked together, etc) then you've just described the thought process that led to Corda. ie a blockchain-inspired decentralised database.